An English version of this article is not yet available.
【調査ログ】SupabaseのEgressが突然70倍に…!?原因調査と対応の記録
supabaseのアウトバウンド量がとある日をきっかけに倍増してしまったので

こんにちは!
この記事は、カチッとした技術解説というよりは、日々の実務で見つけた「生の知見」を書き残しておくスクラップ記事です。
チュートリアル的な内容ではありませんが、実務の中での発見をシェアすることで、誰かのトラブル解決の手がかりになれば嬉しいです。特に大きなオチはありませんが、現場のリアルな試行錯誤を書き留めておきます。
今日のテーマは、「ある日突然、SupabaseのEgress(データ転送量)が70倍に跳ね上がった原因を調査した件」についてです。
そもそも「Egress」って何?
Supabaseを使っていると避けて通れないのが、この Egress(アウトバウンド通信量) という課金項目です。
ざっくり言うと、「Supabase(DB)から外にデータを出した量」のこと。データベースから大量のレコードを SELECT して、アプリ側で受け取れば受け取るほど、この従量課金が乗っていく仕組みです。クラウドサービスではよくある項目ですね。
ちなみに、執筆時点(2026年5月)の料金体系はこんな感じです。
- 200GBまで: 無料枠
- 200GBを超えると: 300GB単位で $4.5 課金
初期の一般的なシステムなら無料枠〜数百GBで収まることが多いのですが、今回のご相談では、デイリーのEgress値がある日を境に突然70倍になっていました。さすがにこれは見過ごせません。
原因調査:どこからデータが漏れている?
これといった心当たりがない状態からのスタートでした。
まずは原因箇所を特定するために、どの経路から大量のデータが引っ張られているのかを絞り込んでいきます。
1. 経路の調査
便利なSupabaseですが、ダッシュボードから見られるEgress情報は、実は「日別の合計量」くらいです。細かい時間単位の推移や、どのクエリが犯人なのかは一目ではわかりません。
ただ、Usageページの 経路別チャート(https://supabase.com/dashboard/org/{hogehoge}/usage#egress)を見ると、どこが怪しいかの比率はわかります。
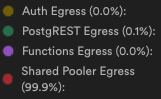
- Auth
- function
- REST
- shared pooler ← 今回はここ!
今回の原因は、API経由(REST)ではなく、shared pooler を介してDBを直接叩いている処理だと判明しました。
2. クエリの特定(pg_stat_statementsを駆使する)
さて、具体的にどのクエリが原因でしょうか? 今回はpooler経由なので、SupabaseのAPI Gatewayにログが残りません。さらに、まだ観測環境(スナップショットなど)が整っていないフェーズだったため、SQLを直接叩いて目星をつけることにしました。
「重たいSELECT処理」を探すために使ったのがこちらのSQLです。
select substring(query, 1, 100), calls, rows,
(rows::float / nullif(calls, 0))::int as rows_per_call
from pg_stat_statements
where query ilike 'select%'
order by rows desc
limit 30;
これを実行すると、「どのテーブルから」「どんな条件で」大量のデータを取得しているかが一発で見えてきます。 ※ pg_stat_statements は実行時期で絞り込めないのが難点ですが、あたりをつけるには十分強力です。
検証と対策
クエリとテーブルが絞り込めたら、該当するエンドポイントやバッチ処理のコードを調査します。 修正方針が決まったら、ステージング環境で計測を行いました。
先ほども触れた通り、shared poolerだと時間単位の実行記録が残らないので、検証には pg_stat_statements_reset() を活用しました。
- 検証前に
select count(*) from pg_stat_statements;で回数確認 - 一度統計をリセットする
pg_stat_statements_reset() - 修正前後の処理を動かして回数を比較する
select count(*) from pg_stat_statements;
地道ですが、このステップを踏むことで「本当にこの修正でデータ転送量が減るのか」を確実に裏取りできました。
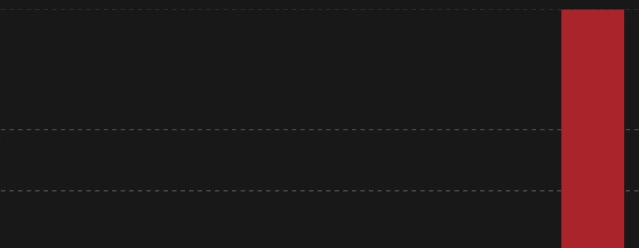
調査結果:Egressを1/10に削減!
結果として、Egressの数値を無事に10分の1まで抑えることができました!
Before
After
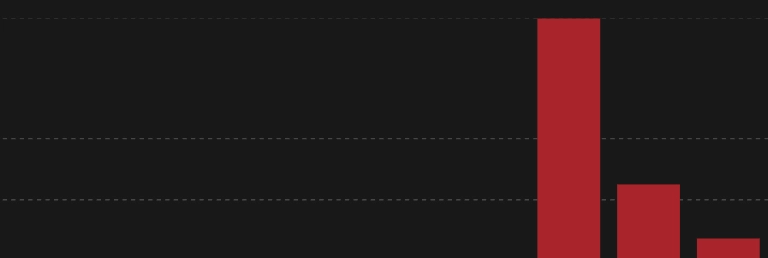
「元の水準」まで完全に落とし切るには、まだロジックや設計の根本的な見直しが必要そうですが、まずは致命的なスパイクを抑えるという応急処置としては大成功です。
目新しいことも特別なこともやっていませんが、こういった地道な作業がとても大事だと痛感します。
最後に
幸いにも早い段階で気づくことができて良かったです。
最初は「もしかして攻撃を受けている…?」とヒヤヒヤしましたが、原因はバッチ処理の設計ロジックでした。
システムが無事にリリースされてユーザーが増えてくると、機能開発だけでなく、こうした「システム運用」の課題が次々と現れます。
ビジネス優先でどうしても後回しになりがちな部分ですが、観測環境(ツール・人員・時間)については早めに意識しておけると安心ですね。
もし内容に間違いなどあれば、LinkedIn経由で教えていただけると助かります! また、「うちのシステム運用、もっと改善したい」「計測周りを相談したい」といったお話も、お気軽にLinkedInからカジュアルにご連絡ください。一緒に悩みましょう!
(※営業DMはご遠慮ください)